Runway GEN-3: Guide to Mastering Prompts
Runway ML’s Gen-3 has arrived, marking an important advancement in the world of AI video generation. As the successor to the well-known Gen-2 model, Gen-3 is bringing us into a new era of AI-driven video creation. In this guide, I will share everything I’ve learned after extensively researching, testing, and studying this new model.
A Quick Look: Gen-2 vs. Gen-3
Before we get into the Gen-3, I wanted to take a moment to show just how far we’ve come. Back in April 2023, I posted a first look at Gen-2, which, at the time, only allowed for basic text-to-video generation.
It was a bit charming, warpy and morphing. However, this morning, I decided to revisit that same project using Gen-3, and here’s what I got:
The improvement is pretty significant, and this is just the beginning.
Understanding Prompting in Gen-3
The way you create prompts in Gen-3 is more flexible and descriptive compared to earlier models. You don’t need to focus as much on bombarding the prompt with keywords.
For example, if you use the prompt:
“The man in black fled across the desert, and the Gunslinger followed.”
It’s pretty decent, though it has some quirks—like the man in black holding an umbrella out of nowhere. Adding more details to the prompt can result in a much-improved output.
Let’s try a longer version of the prompt:
“Long shot in the distance. A man in black robes calmly walks across a vast desert wasteland. The camera orbits to reveal a Gunslinger watching him with steely resolve.”
The result is vastly improved, though there are still some minor issues. Nonetheless, this showcases how more detailed prompting can lead to better results in Gen-3.
What Makes a Good Prompt in Gen-3?
There isn’t necessarily a “right” or “wrong” way to write prompts, but some elements can help improve your results.
I suggest focusing on the following sections:
Subject: This is the person, place, or object you want to focus on in your shot.
Action: What is your subject doing? Walking? Dancing?
Add adjectives to make the action more specific (e.g., “angrily walking” or “dancing happily”).
Setting: Where is the scene taking place? In a castle? On a busy city street?
Don’t be afraid to add mood descriptors like “stormy clouds” or “a sunny day.”
Shot Type: Are you looking for a wide angle, close-up, or long shot?
These terms are essential to help the model understand how to frame the scene.
A Closer Look at Shot Types in Gen-3
In Gen-3, shot types can dramatically impact the outcome of your generation.
Here are a few types you might want to experiment with:
- Wide Angle: Capture a broad view of the scene.
- Close-Up: Focus on specific details or facial expressions.
- Long Shot: Show the entire subject from a distance.
RunwayML Multi-Speaker Lip Sync
Experimenting with Styles
The style section of your prompt helps guide the overall aesthetic or tone of the video. Keywords like “cinematic,” “film noir,” or even “IMAX” can add dramatic flair to your creations.
For instance, if I prompt:
“A woman striding through a misty forest wearing a leather jacket.”
However, by adding the keyword “IMAX,” the same prompt results in something more striking:
It’s a small change, but it makes a noticeable difference.
Addressing Prompt Adherence in Gen-3
Gen-3 tries really hard to follow the instructions given in your prompt. Sometimes, if the model can’t fully achieve what you’ve asked for, it might add a dissolve or cut to accommodate the instructions.
For example, when I tried the prompt:
“A woman’s green eye in a macro shot. The camera pulls out to reveal the interior of an industrial spaceship with a muted, cold atmosphere.”
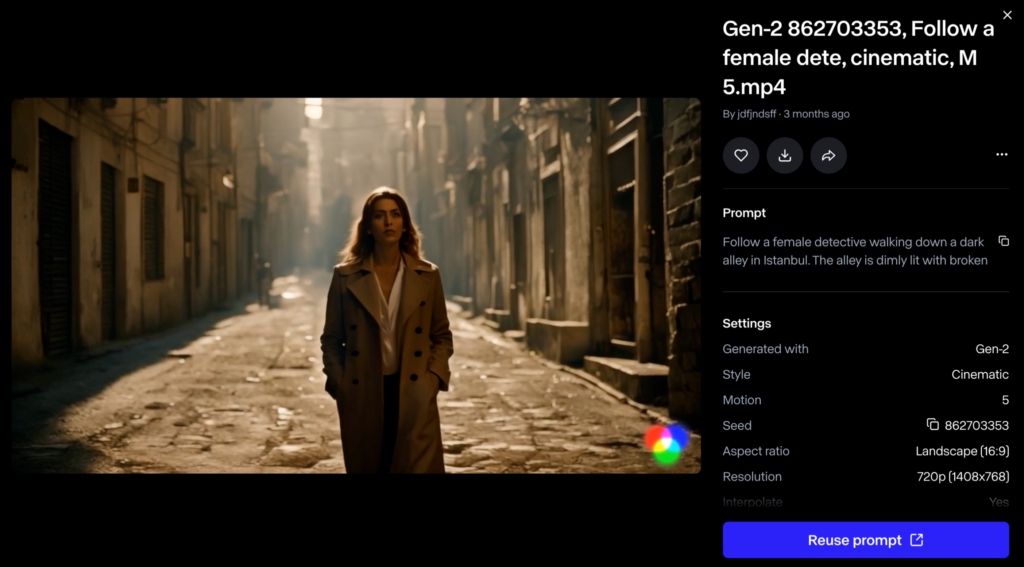
As you can see, while it does start with a macro shot of the eye, it dissolves into another scene. This kind of morphing is something you might notice while using the model.
Maintaining a Consistent Look
If you like a specific generation and want to create variations, Gen-3 allows you to reroll prompts while maintaining some stylistic consistency.
For instance, I created a music video for Radiohead’s “Exit Music (For a Film)” using this technique. Here’s what it looked like:
I used the seed function to maintain the overall look across different scenes. By copying the seed and reusing it in subsequent generations, you can achieve a similar vibe without ending up with the exact same output.
Community Ideas on Prompting
One of the most interesting discoveries from the community comes from Tom Blake, who noted that adding the word “suddenly” to a prompt can lead to dynamic results.
I tried it out with the prompt:
“Rain falling over a city. Suddenly, we zoom down to the street and enter the POV of someone running into a coffee shop.”
The result was quite compelling:
Though the character didn’t quite make it into the coffee shop, the intensity of the rain and the overall atmosphere were captured well.
Text in Gen-3
Another feature in Gen-3 is the ability to generate text within video scenes. One impressive example by Blaine Brown mimics the opening sequence of the Marvel Cinematic Universe (MCU):
“A close-up of superhero comic book pages flipping, with narrow depth of field on a wooden table. As the camera zooms out, the words ‘bzen’ are revealed in 3D letters, textured with comic panels.”
I attempted to recreate this prompt using my name, but ran into errors. It seems Gen-3 has restrictions around using specific keywords like “Marvel” or “MCU.” However, there are ways to work around that by rephrasing or generalizing the terms.
Final Thoughts on Gen-3 Prompting
Gen-3 is incredibly powerful, but it’s not without its quirks. While prompt structure and specific keywords can help, sometimes less is more. You might find that a simple prompt can yield unexpectedly awesome results.
For example, I once generated:
“A puppet talking to a man who clearly doesn’t want to be talking to a puppet.”
The result was pure comedy gold!
In summary, keep experimenting, test different prompt styles, and don’t be afraid to try something unconventional. Gen-3 has a lot to offer, and with creativity.